Audrey TjokroI am an early-career researcher and ML/AI engineer with hands-on experience in computer vision, ML systems, and hardware optimization. My longer-term goal is a PhD at the intersection of AI, computer vision, and cognitive science. I'm seeking full-time research roles starting Summer/Fall 2026 -- ideally at labs working on spatial AI, generative models, or cognitive science. I have an MS in Information Science and Computer Engineering from Cornell Tech, where I am grateful to have worked with Wendy Ju and Andrew Owens, and was a teaching assistant for Alex Conway (CS5112). I have a BA in Information Systems from the University of Washington. Former technical product manager with 4+ years of experience in management consulting. If you're a researcher or lab working in related areas and open to potential collaboration or mentorship, I’d love to connect. Email / GitHub / Google Scholar / LinkedIn |

|
ResearchI'm interested in machine learning, computer vision, graphics, and hardware systems. With a growing interest in cognitive science and what it reveals about how intelligent systems learn. |
|
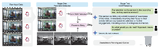
Using Vision-Language Models as Proxies for Social Intelligence in Human-Robot InteractionFrank Bu, Melina Tsai, Audrey Tjokro, Tapomayukh Bhattacharjee, Jorge Ortiz, Wendy Ju CVPR Workshops (Computer-Vision-in-the-Wild), 2026 arxiv / How do robots decide when to engage with people? We deployed a mobile service robot in a university cafe for five days, studying how people signal interaction readiness through nonverbal cues like gaze and proximity. We propose a lightweight two-stage pipeline that uses these cues to selectively trigger VLM queries at socially meaningful moments — enabling robots to engage naturally without constant heavy inference. |
ProjectsThese include coursework, side projects and unpublished research work. |
|
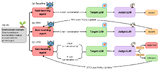
Adversarial Multi-Turn Dynamics: Red-Teaming Clinical LLMs with RLHFCornell CS5788: Generative Models 2026-05-01 paper / Using Reinforcement Learning with Human Feedback, we propose training autonomous Red-Teaming Agents and comparing the efficacy of two distinct alignment algorithms: Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO). Our agents will iteratively converse with a target clinical LLM within a strict 5-turn limit. By optimizing the attacker policies to maximize the target model’s generation of harmful clinical content, we aim to systematically expose and analyze multi-turn vulnerabilities that break through current safety benchmarks. |

|
EmpireHacks 2026 Hackathon Win: DarcMindCornell Hackathon: EmpireHacks 2026 2026-03-22 project page / video / At the EmpireHacks 2026 Hackathon, my team built an DarcMind, an AI agent for Dungeon Masters (DMs) for the tabletop RPG Dungeons & Dragons. A DM can record a session and turn the transcript into live campaign updates: NPC status, lore and plot threads, revealed secrets, and character locations on the campaign map. This lets the DM focus on the more exciting parts of the game like storytelling and world building. Out of 50+ teams, we placed 1st in the Sidekick track and top 4 overall. |

|
Enhancing Video Vision-Language Models for Camera and Scene UnderstandingCornell CS5787: Deep Learning 2025-12-03 paper / Explored how video vision-language models (V-VLMs) understand camera motion and scene geometry, a persistent weakness in modern multimodal systems. While models like GPT-4o and Gemini 2.5 Pro recognize semantic content well, they often misinterpret egomotion—confusing pans, zooms, and translations for incorrect scene changes. |
|
Real-time WebGL PBR Material RendererCornell 2025-08-13 project page / As someone interested in computer vision who had zero graphics programming experience, I built this real-time PBR material renderer from scratch using WebGL 2.0 to bridge the gap between my CV background and 3D graphics fundamentals. This project taught me the mathematical foundations of physically-based rendering, shader programming, and how light interaction models that power modern game engines and visualization tools actually work under the hood. |

|
Auto Ethnography VLMCornell Interaction Research Lab 2025-07-20 project page / Built an automated annotation pipeline using Google’s Gemini Vision-Language Model (VLM) to analyze human-robot interactions in urban deployment footage. This tool enables scalable video ethnography by generating structured JSON annotations of social behaviors—such as approaching, photographing, or helping—directly from raw video frames, reducing researcher annotation time from hours to minutes. |

|
Training Diffusion Models from ScratchCornell CS5670: Computer Vision 2025-05-06 Implemented and trained diffusion models from scratch on MNIST, progressing from single-step denoisers to full DDPM with class conditioning and classifier-free guidance. Built complete UNet architectures with time and class embedding for controlled generation. I got a chance to deep dive into generative model training from first principles, implementing both foundational algorithms and state-of-the-art techniques like CFG for controlled high-quality generation. |


|
The Power of Diffusion ModelsCornell CS5670: Computer Vision 2025-04-25 Implemented the complete diffusion model sampling pipeline using DeepFloyd IF, exploring cutting-edge applications including inpainting, visual anagrams, and hybrid images. Built the DDPM sampling loop from scratch and applied classifier-free guidance for high-quality generation. I have hands-on experience with state-of-the-art generative AI, implementing both foundational algorithms and novel creative applications that push the boundaries of image synthesis. |


|
Neural Radiance Fields (NeRF)Cornell CS5670: Computer Vision 2025-03-28 Implemented Neural Radiance Fields (NeRF) from the groundbreaking ECCV 2020 paper, learning to represent 3D scenes as continuous neural functions. Using only 2D images as supervision, trained deep networks to synthesize photorealistic novel views from arbitrary camera positions. I built the neural network design, training optimization, and novel view synthesis evaluation. Achieved >20 PSNR convergence and generated smooth 360° video outputs. |
|
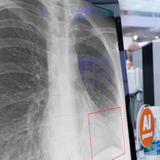
Automated Pneumonia Detection using Deep LearningCornell CS5785: Applied Machine Learning 2024-12-15 project page / This project explores automated pneumonia detection in chest X-rays using three distinct Faster R-CNN implementations with different backbone architectures and optimization strategies. Working with the RSNA Pneumonia Detection Challenge dataset containing over 26,000 chest X-ray images, we implemented and compared PyTorch Faster R-CNN with ResNet-50 and Adam optimizer, Faster R-CNN with ImageNet-pretrained ResNet-50, and PyTorch Faster R-CNN with ResNet-50-FPN and SGD optimizer. |
|
Design and source code from Jon Barron's website |